|
Virtual Human Group
Netease Fuxi AI Lab
We are looking for algorithm interns (PhD/master students) to work in 2023.
Please drop us an email, if you are interested. Contact email: dingyu01@corp.netease.com
|
News
-
[2023-03] Congratulations! Our team is the WINNER (1st) of the EXPR Challenge (Basic Expression Classification) in CVPR 2023.
[2023-03] Congratulations! Our team is the WINNER (1st) of the AU Challenge (facial Action Unit Detection) in CVPR 2023.
[2023-03] Our team is the runner-up (2nd) of the VA Challenge (Valence-arousal estimation) in CVPR 2023.
[2023-02] One paper accepted by IEEE VR. [2023-02] One paper accepted by TVCG. [2023-02] We are pleased to announce the release of a 135-class emotional facial expression [dataset] in response to an invitation from IEEE. [2022-11] Four papers accepted by AAAI 2023. [2022-11] One paper accepted by ICASSP 2023. [2022-10] One paper accepted by IEEE Trans. on Circuits and Systems for Video Technology. [2022-09] One paper accepted by IEEE Trans. on Affective Computing (IF=13.99). [2022-07] Two papers accepted by ACM MM 2022. [2022-03] One paper accepted by IJCAI 2022. [2022-04] Two papers accepted by CVPR 2022. -
[2021-07] Congratulations! Our team is the WINNER (1st) of the EXPR Challenge (Basic Expression Classification) in CVPR 2022.
[2021-07] Congratulations! Our team is the WINNER (1st) of the AU Challenge (facial Action Unit Detection) in CVPR 2022.
[2021-11] Two papers accepted by AAAI 2022. [2021-09] One paper accepted by TVCG. -
[2021-07] Our team is the WINNER (1st) of the EXPR Challenge (Basic Expression Classification) in ICCV 2021.
[2021-07] Our team is the WINNER (1st) of the AU Challenge (facial Action Unit Detection) in ICCV 2021.
[2021-07] Our team is the runner-up (2nd) of the VA Challenge (Valence-arousal estimation) in ICCV 2021.
[2021-03] Two papers accepted by CVPR. [2020-11] One paper accepted by AAAI. [2020-03] One paper accepted by ICASSP. [2020-03] One paper accepted by CVPR.
|
Selected Publications

|
Real-time Facial Animation for 3D Stylized Character with Emotion Dynamics
Ye Pan*, Ruisi Zhang, Jingying Wang, Yu Ding, Kenny Mitchell
ACM Multimedia, 2023
|

|
Face Identity and Expression Consistency for Game Character Face Swapping
Hao Zeng, Wei Zhang, Keyu Chen, Zhimeng Zhang, Lincheng Li, Yu Ding*
Computer Vision and Image Understanding, 2023
|

|
Detecting Facial Action Units from Global-Local Fine-grained Expressions
Wei Zhang, Lincheng Li, Yu Ding*, Wei Chen, Zhigang Deng, Xin Yu
IEEE Transactions on Circuits and Systems for Video Technology, 2023
|
|
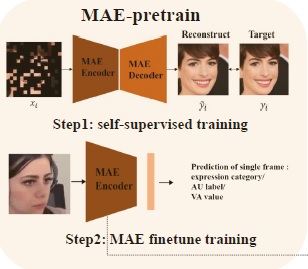
Multi-modal Facial Affective Analysis based on Masked Autoencoder
Wei Zhang, Bowen Ma, Feng Qiu, Yu Ding*
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
|
|
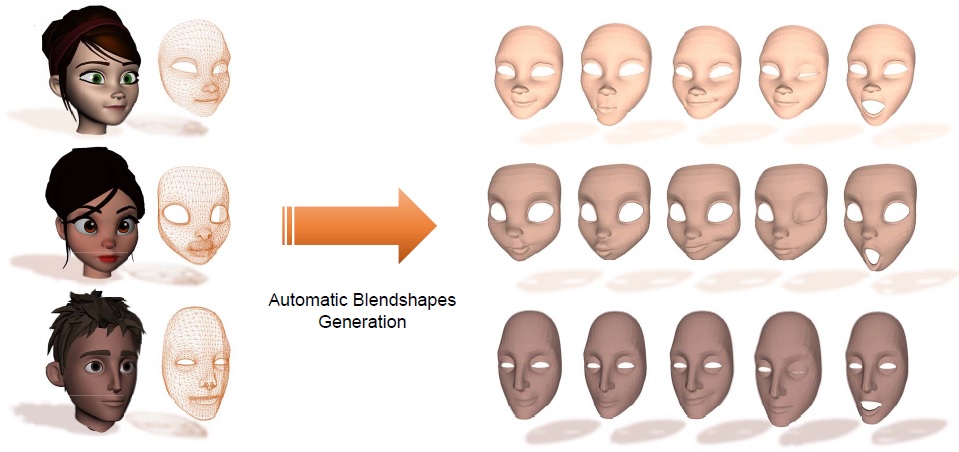
Fully Automatic Blendshape Generation for Stylized Characters
Jingying Wang, Yilin Qiu, Keyu Chen, Yu Ding, Ye Pan*
IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR), 2023
|

|
Emotional Voice Puppetry
Ye Pan*, Ruisi Zhang, Shengran Cheng, Shuai Tan, Yu Ding, Kenny Mitchell, Xubo Yang
IEEE Transactions on Visualization and Computer Graphics (IEEE TVCG), 2023
|

|
StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles
Yifeng Ma, Suzhen Wang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding*, Zhidong Deng*, Xin Yu
AAAI Conference on Artificial Intelligence (AAAI), 2023 (oral presentation)
|

|
DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
Zhimeng Zhang, Zhipeng Hu, Wenjin Deng, Changjie Fan, Tangjie Lv, Yu Ding*
AAAI Conference on Artificial Intelligence (AAAI), 2023
|
|
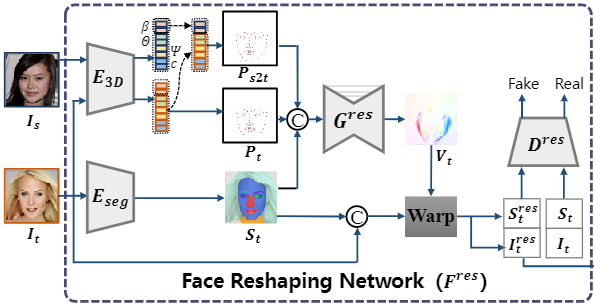
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
Hao Zeng, Wei Zhang, Changjie Fan, Tangjie Lv, Suzhen Wang, Zhimeng Zhang, Bowen Ma, Linchang Li, Yu Ding*, Xin Yu
AAAI Conference on Artificial Intelligence (AAAI), 2023
|
|
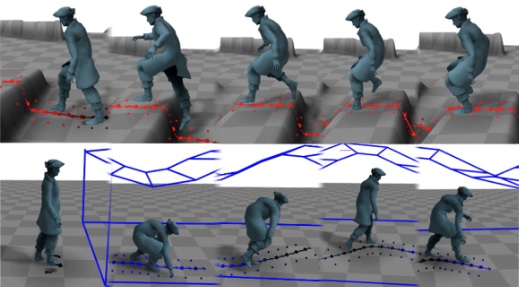
Multi-Scale Control Signal-Aware Transformer for Motion Synthesis without Phase
Lintao Wang, Kun Hu*, Lei Bai, Yu Ding, Wanli Ouyang, Zhiyong Wang
AAAI Conference on Artificial Intelligence (AAAI), 2023
|
|
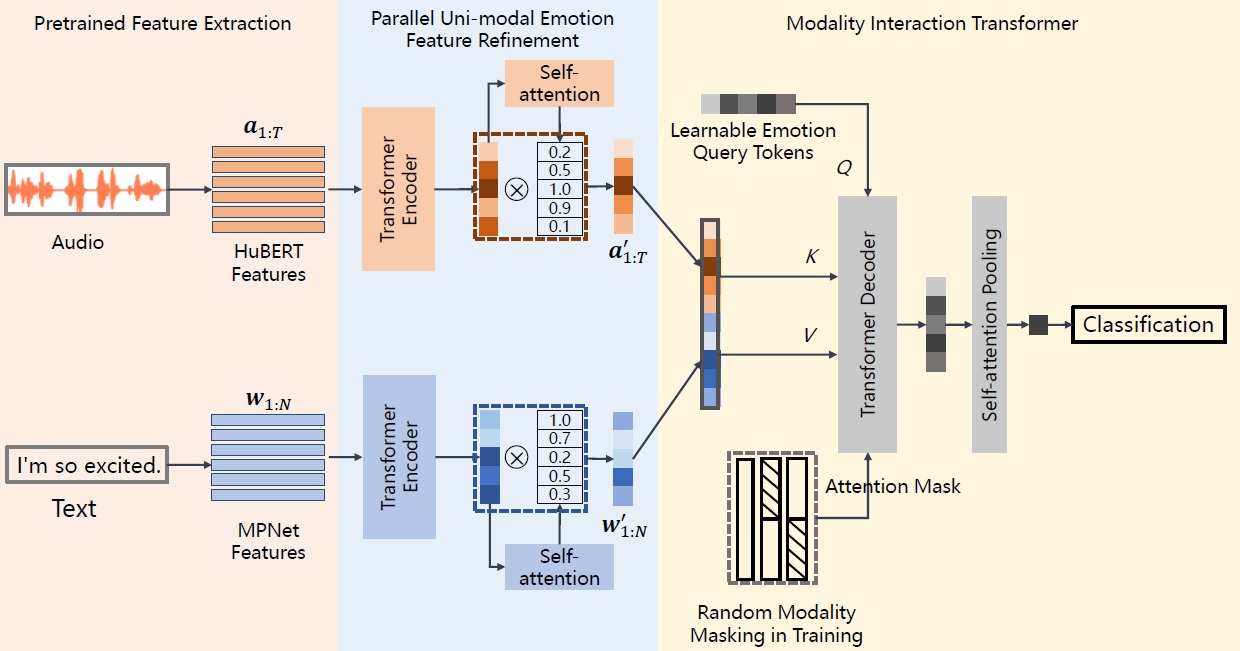
Exploring Complementary Features in Multimodal Speech Emotion Recognition
Suzheng Wang, Yifeng Ma, Yu Ding*
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
|
|
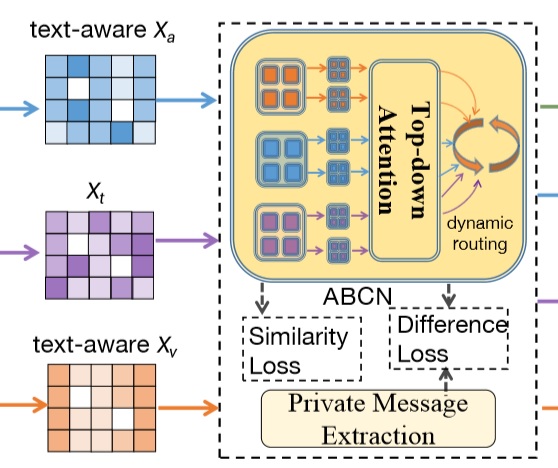
BAFN: Bi-direction Attention based Fusion Network for Multimodal Sentiment Analysis
Jiajia Tang, Dongjun Liu, Xuanyu Jin, Yong Peng, Qibin Zhao, Yu Ding, Wanzeng Kong*
IEEE Transactions on Circuits and Systems for Video Technology, 2022
|
|
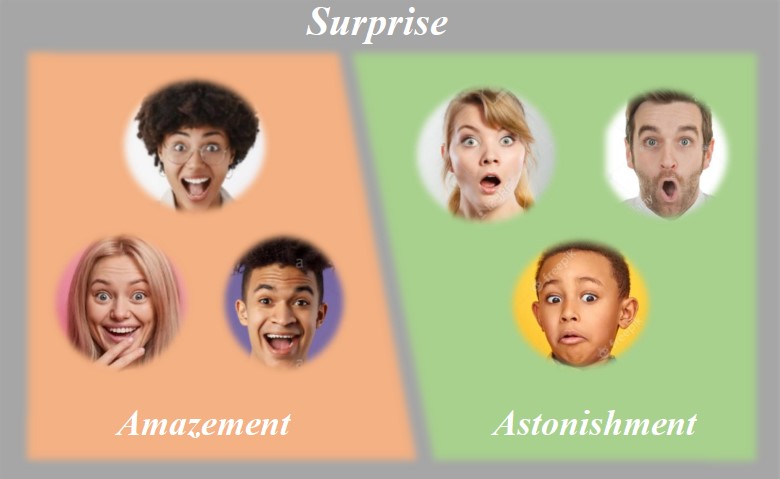
Semantic-Rich Facial Emotional Expression Recognition
Keyu Chen, Xu Yang, Changjie Fan, Wei Zhang, Yu Ding*
IEEE Transactions on Affective Computing (IF=13.99), 2022
|
|
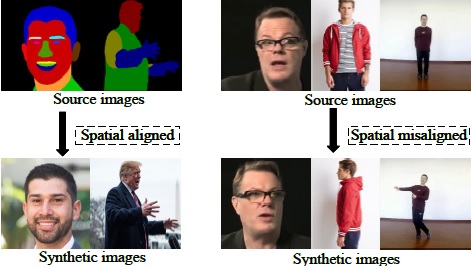
Adaptive Affine Transformation: A Simple and Effective Operation for Spatial Misaligned Image Generation
Zhimeng Zhang, Yu Ding*
ACM International Conference on Multimedia (ACMMM), 2022
|
|
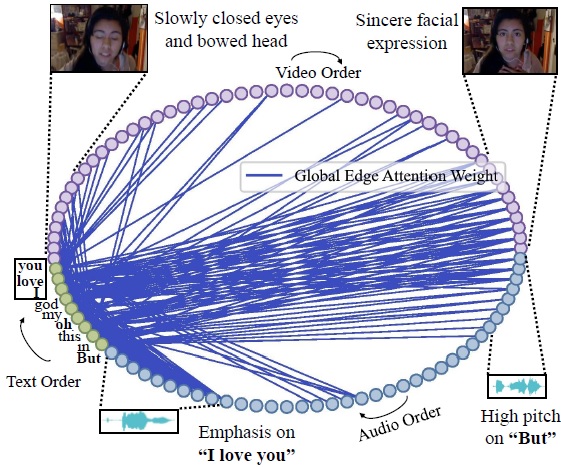
Dynamically Adjust Word Representations Using Unaligned Multimodal Information
Jiwei Guo, Jiajia Tang, Weichen Dai, Yu Ding, Wanzeng Kong*
ACM International Conference on Multimedia (ACMMM), 2022
|
|
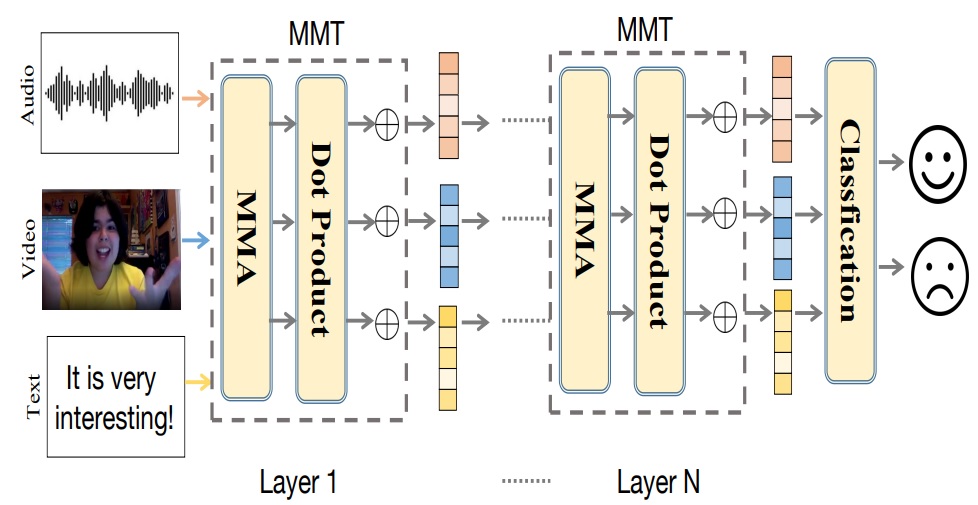
MMT: Multi-way Multi-modal Transformer for Multimodal Learning
Jiajia Tang, Kang Li, Ming Hou, Xuanyu Jin, Wanzeng Kong*, Yu Ding, Qibin Zhao
International Joint Conference on Artificial Intelligence (IJCAI), 2022 (13.9% acceptance rate)
|
|
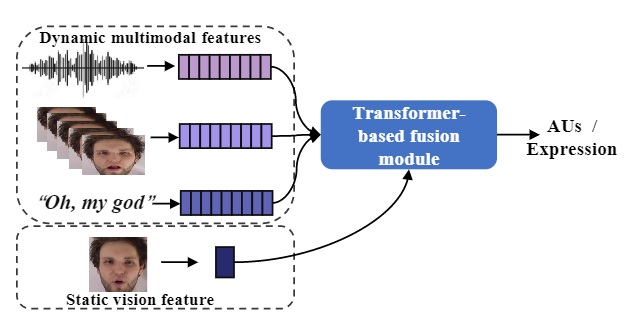
Transformer-based Multimodal Information Fusion for Facial Expression Analysis
Wei Zhang, Feng Qiu, Suzhen Wang, Hao Zeng, Zhimeng Zhang, Rudong An, Bowen Ma, Yu Ding*
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
|
|
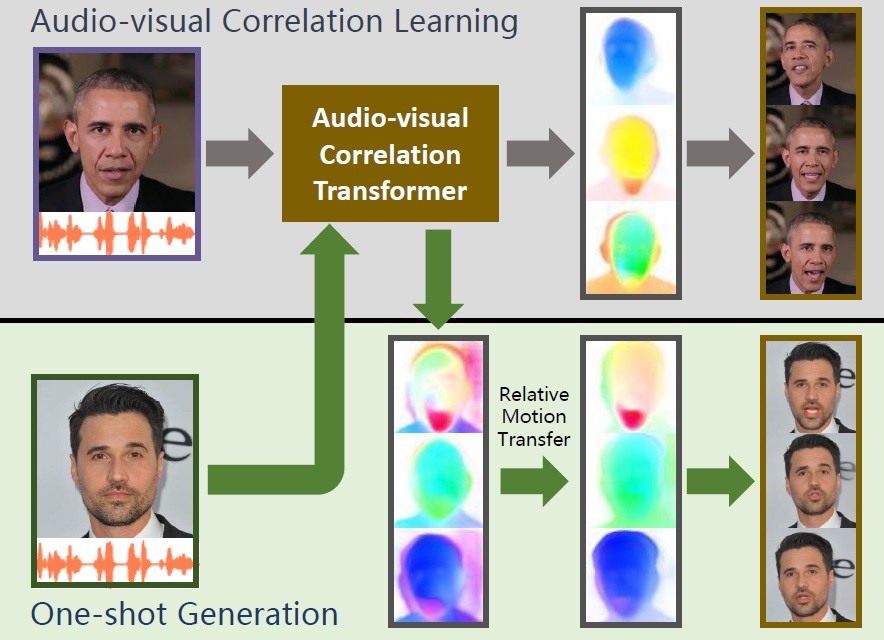
One-shot Talking Face Generation with Single-speaker Audio-Visual Correlation Learning
Suzhen Wang, Lincheng Li, Yu Ding*, Xin Yu
AAAI Conference on Artificial Intelligence (AAAI), 2022
|

|
Multi-Dimensional Prediction of Guild Health in Online Games: A Stability-Aware Multi-Task Learning Approach
Chuang Zhao, Hongke Zhao*, Runze Wu*, Qilin Deng, Yu Ding, Jianrong Tao, Changjie Fan
AAAI Conference on Artificial Intelligence (AAAI), 2022
|

|
Paste You Into Game: Towards Expression and Identity Consistency Face Swapping
Hao Zeng, Wei Zhang, Keyu Chen, Zhimeng Zhang, Lincheng Li, Yu Ding*
IEEE Conference on Games (CoG), 2022
|

|
A Music-driven Deep Generative Model for Guzheng Playing Animation
Jiali Chen, Changjie Fan, Zhimeng Zhang, Gongzheng Li, Zeng Zhao, Jiajun Bu, Zhigang Deng, Yu Ding*
IEEE Transactions on Visualization and Computer Graphics (TVCG)
|
|
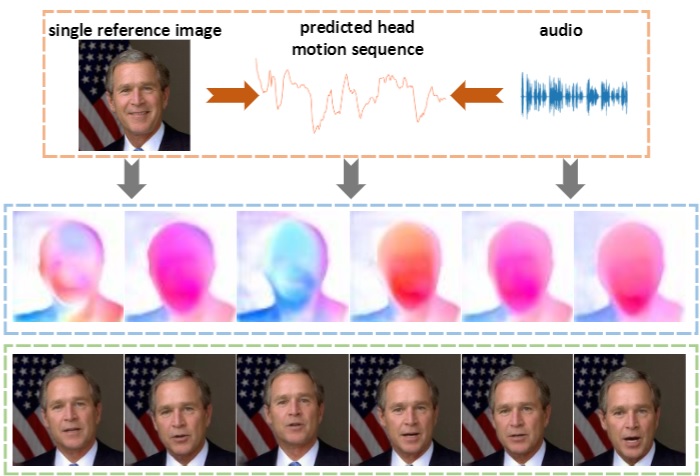
Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
Suzhen Wang, Lincheng Li, Yu Ding*, Changjie Fan, Xin Yu,
International Joint Conference on Artificial Intelligence (IJCAI), 2021.
|
|
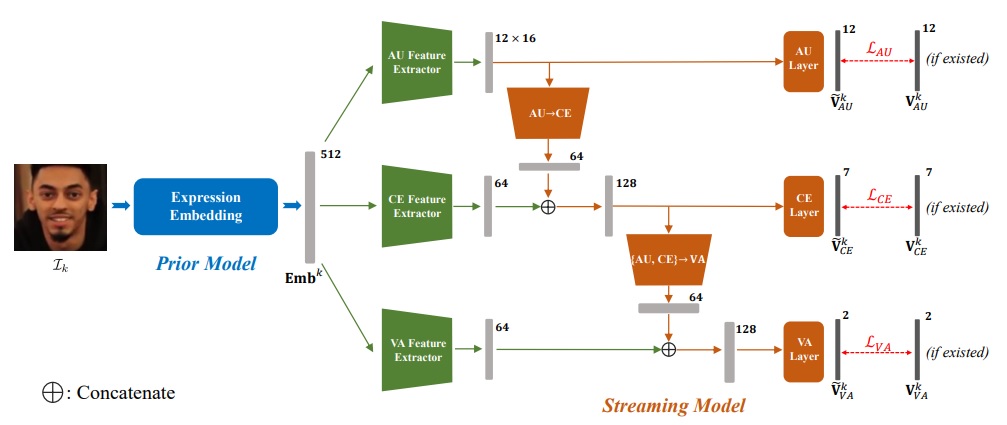
Prior Aided Streaming Network for Multi-task Affective Analysis
Wei Zhang, Zunhu Guo, Keyu Chen, Lincheng Li, Zhimeng Zhang, Yu Ding, Runze Wu, Tangjie Lv, Changjie Fan
International Conference on Computer Vision (ICCV), 2021
|
|
Prior aided streaming network for multi-task affective recognitionat the 2nd abaw2 competition
Wei Zhang, Zunhu Guo, Keyu Chen, Lincheng Li, Zhimeng Zhang, Yu Ding*
ICCV-ABAW2 competitions, 2021
1st place in both EXPR and AU Challenges and 2nd place in the VA Challenge
|
|
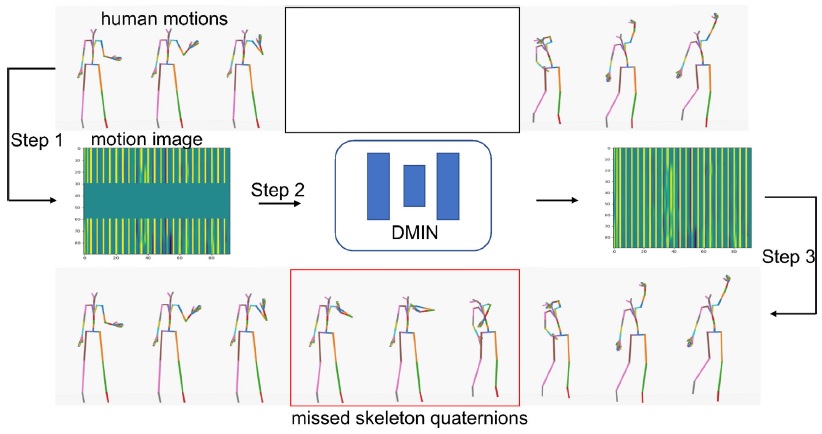
Learning a deep motion interpolation network for human skeleton animations
Chi Zhou, Zhangjiong Lai, Suzhen Wang, Lincheng Li, Xiaohan Sun, Yu Ding*
Computer Animation and Virtual Worlds, 2021.
|
|
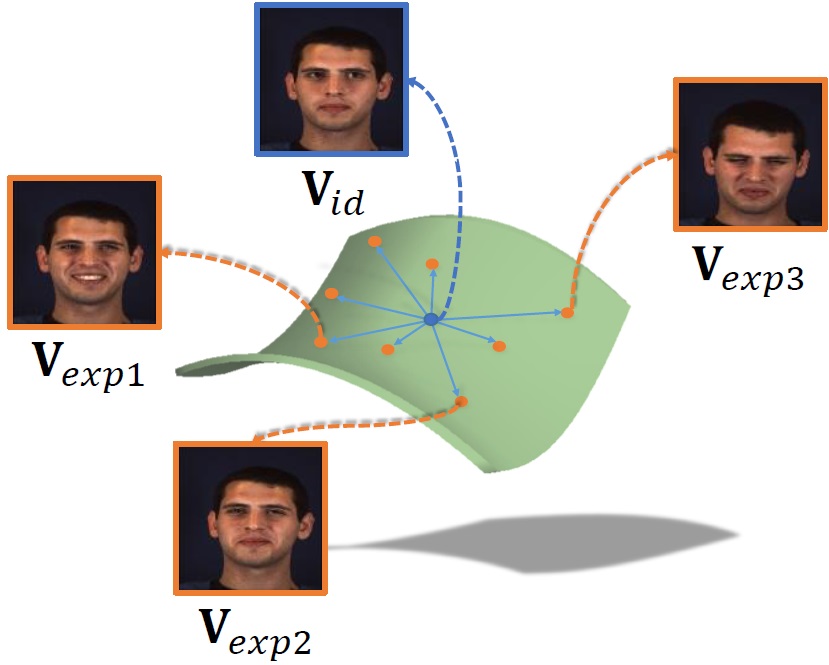
Learning a Facial Expression Embedding Disentangled From Identity
Wei Zhang, Xianpeng Ji, Keyu Chen, Yu Ding*, Changjie Fan
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
[pdf]
|
|
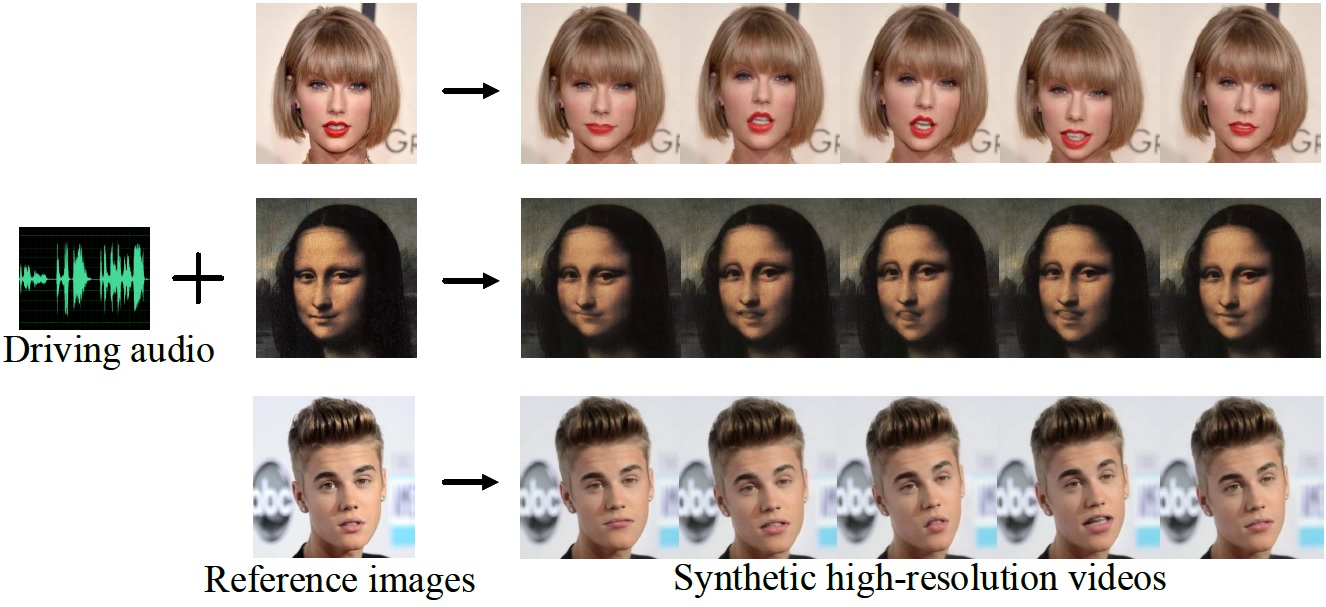
Flow-Guided One-Shot Talking Face Generation With a High-Resolution Audio-Visual Dataset
Zhimeng Zhang, Lincheng Li, Yu Ding*, Changjie Fan
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[pdf]
[video]
|

|
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
Lincheng Li, Suzhen Wang, Zhimeng Zhang, Yu Ding*, Yixing Zheng, Xin Yu, Changjie Fan
AAAI Conference on Artificial Intelligence (AAAI), 2021.
[pdf]
[video]
|
|
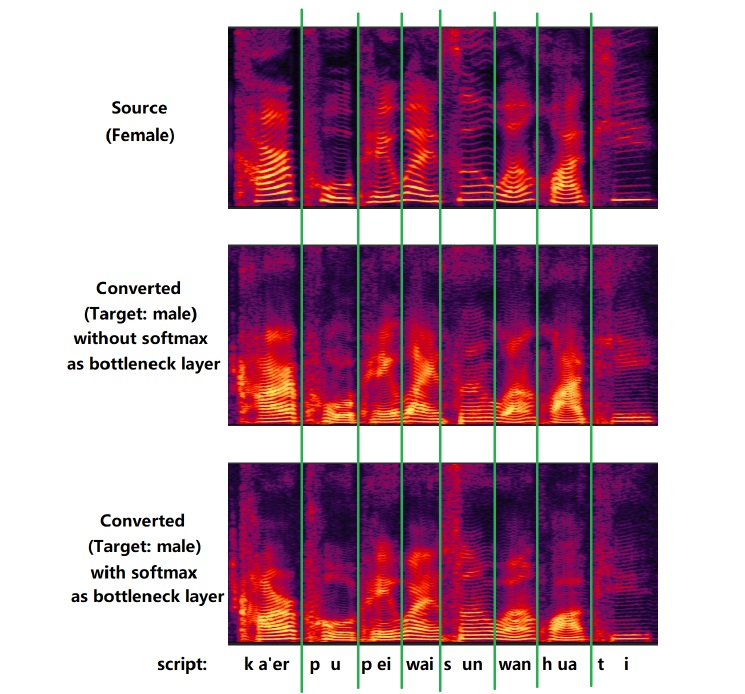
One-Shot Voice Conversion Using Star-Gan
Ruobai Wang, Yu Ding*, Lincheng Li, Changjie Fan
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020
[pdf]
|
|
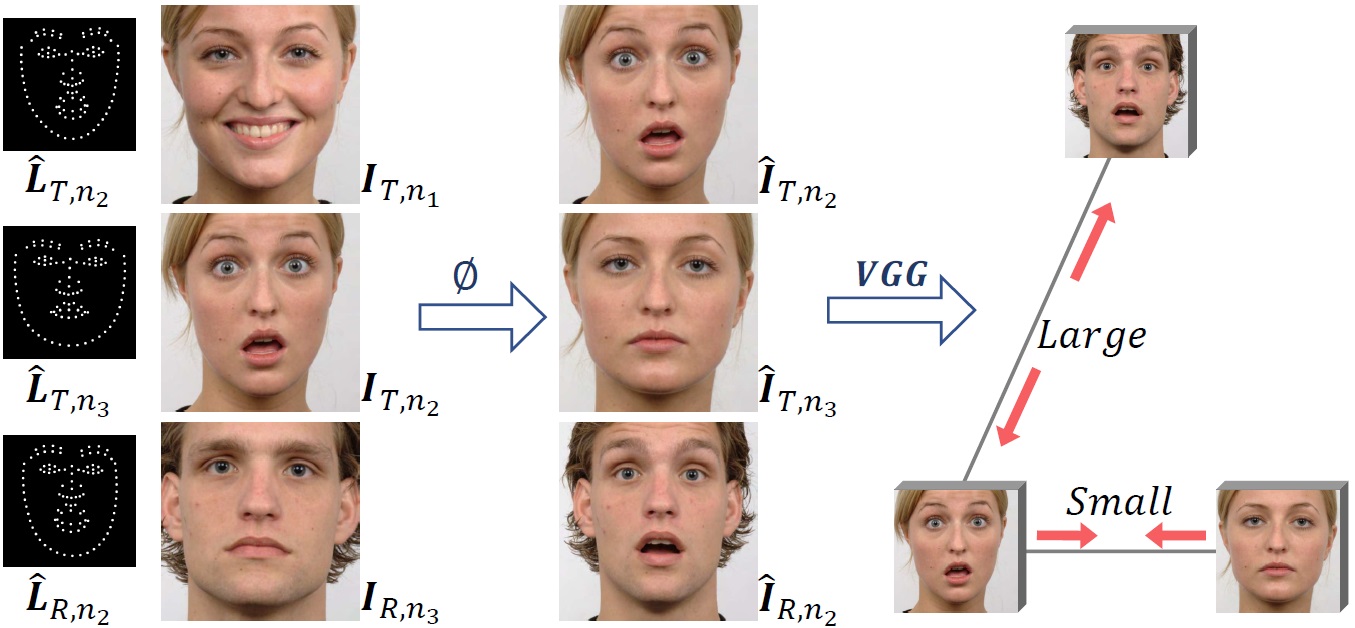
Freenet: Multi-identity face reenactment
Jiangning Zhang, Xianfang Zeng, Mengmeng Wang, Yusu Pan, Liang Liu, Yong Liu, Yu Ding, Changjie Fan
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
[pdf]
[video]
|
|
Text-driven Visual Prosody Generation for Embodied Conversational Agents
Jiali Chen, Yong Liu, Zhimeng Zhang, Changjie Fan, Yu Ding*
ACM International Conference on Intelligent Virtual Agents, 2019
|
|